Credit Card Fraud Detection
Course Project for Data Science & Machine Learning — IISER Bhopal (2022)
Objective
To build a machine-learning system capable of detecting fraudulent credit card transactions. The challenge lies in the extreme class imbalance — genuine transactions vastly outnumber fraudulent ones — making the problem ideal for advanced resampling and model-tuning techniques.
Background
The dataset comprises real-world European credit card transactions (September 2013) with anonymized PCA-transformed features (V1–V28), plus time and amount fields. Only 142 of 56, 974 transactions were fraudulent — roughly 0.25 %, creating a severe imbalance that degrades most standard classifiers.
Methodology
Imbalance Handling: Applied SMOTE (Synthetic Minority Over-sampling Technique) to generate synthetic minority-class samples and Edited Nearest Neighbor (ENN) undersampling for comparison.
Feature Selection: Used SelectKBest with the ANOVA F-test to identify the top four informative components (V3, V10, V12, V22).
Modeling: Implemented three supervised classifiers — Gaussian Naive Bayes, Logistic Regression, and K-Nearest Neighbors — chosen for their interpretability and performance on Gaussian-like, linearly separable data.
Hyperparameter Tuning: Employed GridSearchCV for exhaustive parameter optimization.
Results
The KNN model achieved the highest macro-averaged F-measure (0.90) after feature selection and parameter tuning. Oversampling improved minority-class recall, while feature reduction reduced computation time with minimal accuracy loss.
Figures
Pair Plot of Selected Features: Visualization of the four best PCA components (V3, V10, V12, V22), showing clear class separation.
Results: Comparative precision-recall metrics before and after tuning and resampling.
Impact and Future Work
Demonstrated that lightweight models with careful resampling and tuning can detect fraud effectively without deep learning. Future improvements could integrate SMOTE + ENN hybrids, ensemble voting, or deep architectures for real-time fraud detection on streaming data.

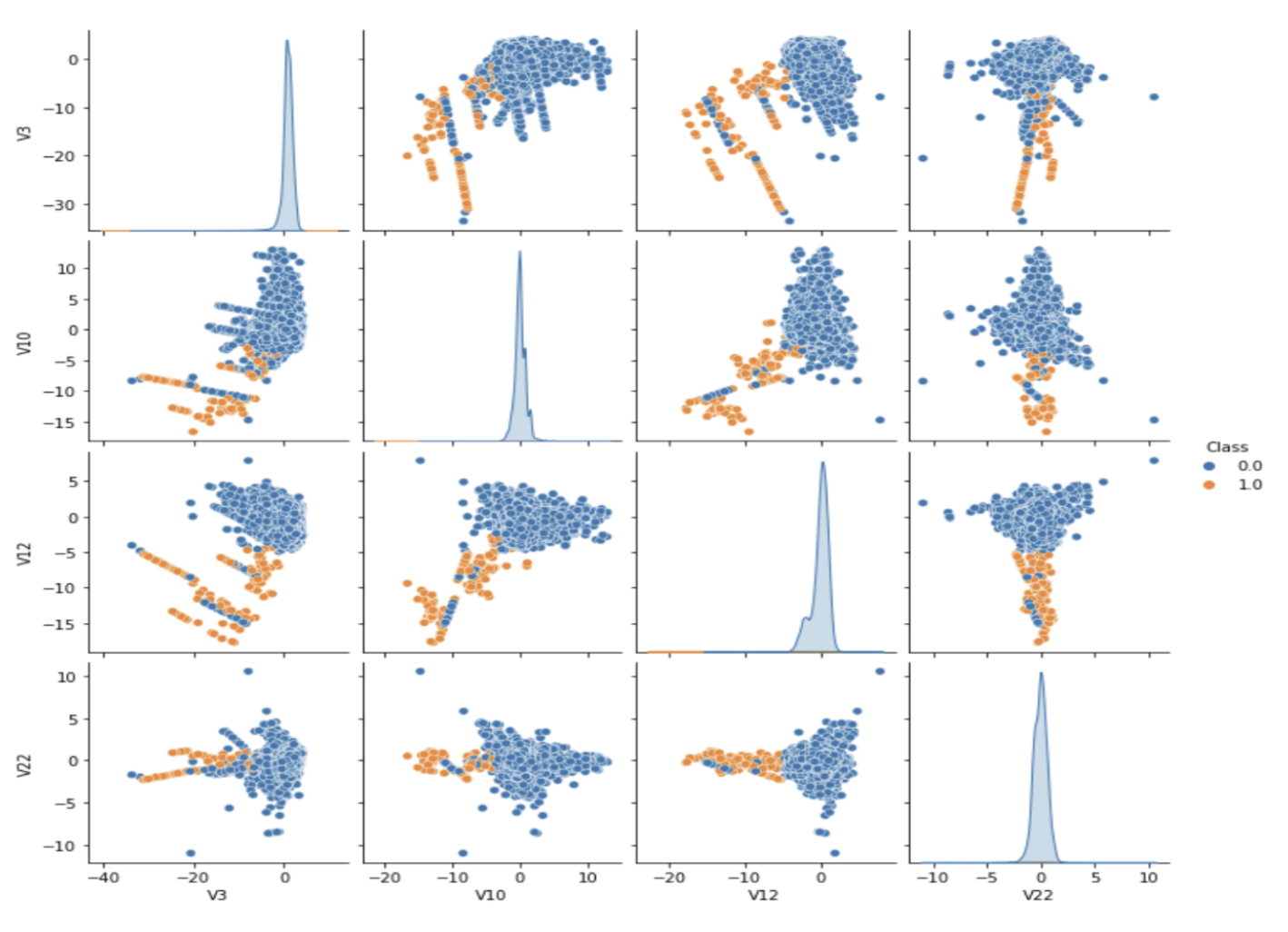
Pair plot of the selected features

Results
The full project report, Credit Card Fraud Detection, is available as a downloadable PDF, and the complete implementation code can be accessed on GitHub.
Project Report: Credit Card Fraud Detection. IISER Bhopal.
Code Repository: GitHub – Credit Card Fraud Detection
This repository includes the full workflow for data preprocessing, class-imbalance correction using SMOTE, feature selection (SelectKBest), model training with Gaussian Naive Bayes, Logistic Regression, and K-Nearest Neighbors, and hyperparameter tuning using GridSearchCV. It also contains Jupyter notebooks, visualizations (including pair plots), and evaluation tables summarizing model performance.